Classification de données hétérogènes
Application au scoring
Collaboration avec Oney Bank, Croix
Le projet
Les méthodes de scoring sont couramment utilisées dans le domaine bancaire pour les demandes de prêts ou des applications marketing. Les données comptent un nombre important de variables hétérogènes ainsi que potentiellement de nombreuses données manquantes. Une contrainte réglementaire s’ajoute également afin que les résultats de la méthode de scoring soient interprétables. Oney Bank utilise actuellement une méthode de régression logistique avec sélection de variables. Cependant cette méthode standard peut souffrir de quelques problèmes en grande dimension (corrélation, instabilité, manque de flexibilité).
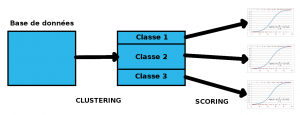
La méthode proposée consiste en un premier temps à appliquer une étape de classification avec le logiciel MixtComp, développé par Inria et le laboratoire Paul Painlevé, puis d’appliquer sur chaque classe obtenue la méthode standard d’Oney Bank. MixtComp va créer des groupes d’individus tout en complétant les données manquantes suivant la distribution au sein des différents groupes. Chaque groupe identifie une structure particulière au sein des données. Appliquer un modèle par groupe permet alors d’expliquer plus de variance dans les données qu’un seul modèle pour l’ensemble des données et de réduire l’erreur de prédiction.
Package/logiciel
Le logiciel MixtComp est disponible en ligne sur MASSICCC (mode SaaS).
Contact
Christophe Biernacki : christophe.biernacki[AT]math.univ-lille1.fr