Co-clustering d’occurences de mots
Application à la classification de rapports d’interventions
Collaboration avec Alstom, Saint Ouen
Le projet
Dans le cadre de la maintenance de divers matériels ferroviaires (par exemple des aiguillages, des bougies de matériels roulants, etc.), la société Alstom consigne l’ensemble de ses interventions dans une base de données spécifique. Il s’agit d’enregistrer l’ensemble des caractéristiques liées à l’incident comme son type, sa description, sa résolution, etc. Cependant, une particularité de cette base est la présence de nombreux champs renseignés en texte libre. Même si le texte libre est très pratique au niveau opérationnel, cela complique nettement la tâche d’analyse a posteriori de cette base de données pour tirer matière à améliorer à terme la qualité des matériels concernés, ou leur maintenance.
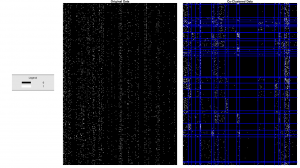
L’analyse de ces données de maintenance passe en particulier par une cartographie des incidents sous forme de regroupements d’événements similaires. Cette étape de classification, très classique, a en effet pour intérêt d’offrir un résumé exploitable de la base initiale, Alstom pouvant se focaliser sur des grands types de défaillances, au départ noyés dans l’ensemble des données disponibles. Cette classification est cependant rendue ici particulièrement délicate car des évenements similaires peuvent être décrits par des mots différents en français ou en anglais (texte libre).
Basée sur un dictionnaire de synonymes fourni par Alstom, l’occurence de chacun de ces mots est calculé pour chaque fiche d’intervention. Le logiciel blockcluster, issu des recherches des chercheurs d’Inria et du laboratoire Paul Painlevé, implémentant une méthode de co-clustering a permis de créer simultanément des groupes de fiches et des groupes de mots clés. Ainsi, un même groupe de fiches décrit des fiches correspondant à des interventions proches au niveau du contenu de la fiche. Les groupes de mots clés peuvent ainsi être intérprétés comme ayant une relation d’association fréquente dans les incidents techniques.
Publication
[1] P.S. Bhatia, S. Iovleff, G. Govaert. blockcluster: An R Package for Model-Based Co-Clustering. Journal of Statistical Software, v. 76, Issue 9, p. 1 – 24, feb. 2017. ISSN 1548-7660.
Package/logiciel
Le package blockcluster peut être téléchargé ici sur le site du CRAN.
Il est également disponible en ligne sur MASSICCC (mode SaaS).
Contact
Serge IOVLEFF : serge.iovleff[AT]univ-lille.fr